使用缓存会存在哪些问题
约 1995 字大约 7 分钟
使用缓存会存在哪些问题
使用缓存常用于缓解数据库压力以及提高查询效率等问题,在高并发场景下,对于不同场景我们都需要使用合理的技术安排确保中间件和数据库做好协调。
5种缓存问题以及对应策略
缓存穿透
问题简介
尽管我们将数据库中某些数据换到到内存中,但是若有些攻击者使用一些数据库中不存在的key进行恶意攻击,这时候,所有的查询请求就像穿透了缓存中间件一样直接在数据库中进行查询操作,在高并发场景,这样的攻击就会使得数据压力过大,从而导致数据库性能瓶颈。
应对策略
- 第一次查询不存在,我们就在redis中缓存该key值,值为null,并设置一个较短的生存时间(这里可能会出现缓存一致性问题,笔者会在后文进行相熟)。
- 在业务上对查询的值进行校验,例如我们的数据库id分为是0-999,攻击者使用的id为-1,这时候我们完全可以在业务代码上进行校验处理。
- 将所有key值缓存到布隆过滤器中,每次查询都到redis的布隆过滤器中进行查询,若查询不存在则直接返回。
缓存击穿
问题概述
和上述问题情况一样,也是缓存中查不到用户数据,大量请求打到数据库上,但是这种情况的发生原因却非恶意攻击者所为,原因大抵如下:
1. 大量用户查询的某个数据,刚刚好在缓存中过期
2. 大量用户查询的值都在数据中,缓存中没有
解决对策
- 设置热点数据永不过期,亦或者一旦有超过多少个用户在单位时间内查询这个数据,我们就给这个缓存续命
- 对重要的接口做好熔断和限流,防止用户进行恶意重刷。
- 加互斥锁(在高并发场景对用户不太友好,不是很建议使用)
缓存雪崩
问题原因
大量缓存数据同一时间到期,所有查询一下子都打到数据库上。导致数据库压力过大进而直接宕机。
解决策略
- 设置热点数据永不过期
- 设置随机过期
缓存污染(缓存空间全满)
问题原因
某些数据查询一次就被缓存在数据库中,随着时间推移,缓存空间已经满了,这时候redis就要根据缓存策略进行缓存置换。这就造成没意义的数据需要通过缓存置换策略来淘汰数据,而且还可能出现淘汰热点数据的情况。
解决方案
选定合适的缓存置换策略,而redis缓存策略主要分三类
不淘汰的
1. noeviction (v4.0后默认的):不会淘汰任何过期键,满了就报错
对设置了过期时间的数据中进行淘汰
2. volatile-random:随机删除过期key
3. volatile-ttl:根据过期时间进行排序,越早过期的数据就优先被淘汰。
4. volatile-lru:即最近最少使用算法,redis的lru缓存置换算法相比传统的算法做了一定优化,根据 maxmemory-samples从缓存中随机取出几个key值,然后进行比较在进行淘汰,这样就避免了缓存置换时需要操作一个大链表进行key值淘汰了。
5. volatile-lfu:lru只知晓用户最近使用次数,而不知道该数据使用频率,所以lfu就是基于lru进一步的优化,进行淘汰时随机取出访问次数最少的数据,如果最少的数据有多个,按按照lru算法进行淘汰。但是redis只用8bit记录访问次数,超过255就无法进行自增了,所以我们可以使用`lfu-log-factor` 和`lfu-decay-time`来用户访问次数增加的频率。
lfu-decay-time:控制访问次数衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。若设置为0,则意味着每次扫描访问次数都会扣减。
lfu-log-factor:用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
从全部数据中进行淘汰
6. allkeys-random:从所有键值对中使用lru淘汰
7. allkeys-lru:从所有键值对中随机删除
8. allkeys-lfu:从所有键值对中使用lfu随机淘汰
具体可以查看redis配置文件描述
MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select one from the following behaviors:
#
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
数据库缓存一致性问题
问题描述
用户某个时间段查询的数据刚刚好被更新,结果用户查到的是老数据,我们可能会想到两种应用方案:
- 若我们先清空缓存再更新:很可能出现,数据清空后,刚刚好有个用户进来从数据库中读到老数据,后续就一直使用老数据。
- 若先更新再更新缓存:刚好更新缓存的时候的线程挂掉,数据不一致问题照样没有得到解决。
解决方案
Cache Aside Pattern(旁路缓存模式)
- 读缓存:先从缓存读,缓存有直接返回,缓存没有去数据库读,在缓存到Redis中。
- 写缓存:先更新数据库,再删除缓存。
这种方案对于情况1并没有很好的解决,但是情况1发生的概率不大,他需要具备以下4个条件
1. 读操作时刚刚好数据失效
2. 读操作要先于写操作,且读操作要比写操作后完成(实际上写操作非常慢,更新还要进行锁表等,所以这一步大概率不会发生,生产环境基本最多出现一次脏数据读取或者根本不会发生这种情况)
针对情况2,我们有3中方案
方案1:若删除失败,我们则将这个key值的过期时间变短(让他秒挂),但是治标不治本,不建议使用。
方案2:我们可以使用队列+重试机制解决问题,整体步骤为
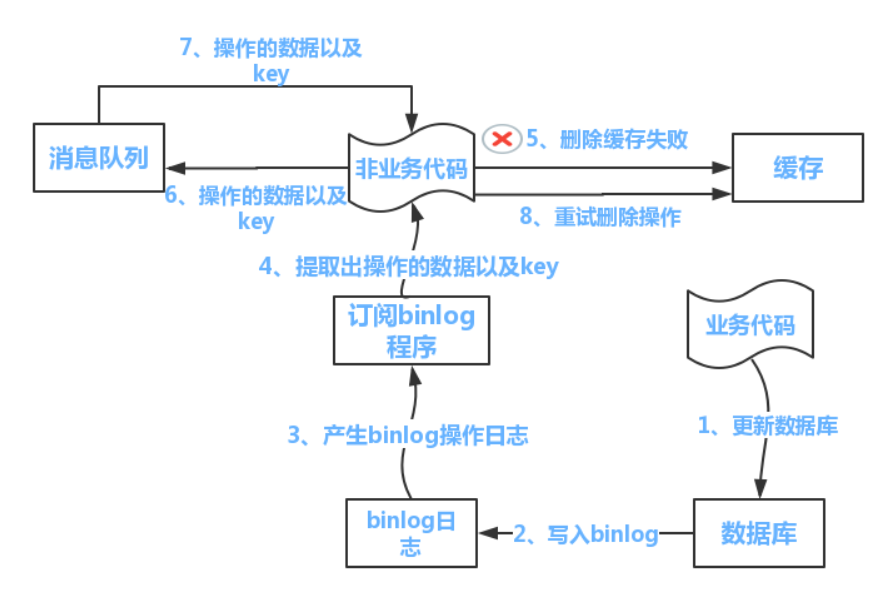
1. 执行数据库更新操作,成功则进行缓存清空
2. 若清空失败,则将这个key发送到消息队列中
3. 业务代码从队列中捞出这个key值进行删除重试直到成功为止
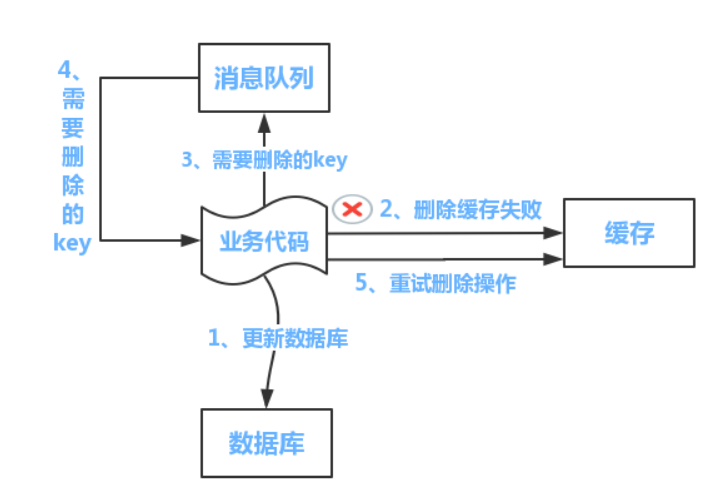
但是缺点也很明显,对于业务代码侵入性太强,所以我们对解决方案进行升级。
方案3:使用一个异步线程去订阅数据库的binlog,然后使用非业务代码进行删除重试