谈谈ThreadLocal
谈谈ThreadLocal
ThreadLocal是什么
ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况;
ThreadLocal类用在哪些场景
一般来说, ThreadLocal在实际工业生产中并不常见, 但是在很多框架中使用却能够解决一些框架问题; 比如Spring中的事务、Spring 中 作用域 Scope 为 Request的Bean 使用ThreadLocal来解决.
ThreadLocal使用方法
1、将需要被多线程访问的属性使用ThreadLocal变量来定义; 下面以网上多数举例的DBConnectionFactory类为例来举例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DBConnectionFactory {
private static final ThreadLocal<Connection> dbConnectionLocal = new ThreadLocal<Connection>() {
@Override
protected Connection initialValue() {
try {
return DriverManager.getConnection("", "", "");
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
};
public Connection getConnection() {
return dbConnectionLocal.get();
}
}
这样在Client获取Connection的时候, 每个线程获取到的Connection都是该线程独有的, 做到Connection的线程隔离; 所以并不存在线程安全问题
ThreadLocal如何实现线程隔离
1、主要是用到了Thread对象中的一个ThreadLocalMap类型的变量threadLocals, 负责存储当前线程的关于Connection的对象, 以dbConnectionLocal 这个变量为Key, 以新建的Connection对象为Value; 这样的话, 线程第一次读取的时候如果不存在就会调用ThreadLocal的initialValue方法创建一个Connection对象并且返回;
具体关于为线程分配变量副本的代码如下:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
1、首先获取当前线程对象t, 然后从线程t中获取到ThreadLocalMap的成员属性threadLocals
2、如果当前线程的threadLocals已经初始化(即不为null) 并且存在以当前ThreadLocal对象为Key的值, 则直接返回当前线程要获取的对象(本例中为Connection);
3、如果当前线程的threadLocals已经初始化(即不为null)但是不存在以当前ThreadLocal对象为Key的的对象, 那么重新创建一个Connection对象, 并且添加到当前线程的threadLocals Map中,并返回
4、如果当前线程的threadLocals属性还没有被初始化, 则重新创建一个ThreadLocalMap对象, 并且创建一个Connection对象并添加到ThreadLocalMap对象中并返回。
如果存在则直接返回很好理解, 那么对于如何初始化的代码又是怎样的呢?
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
1、首先调用我们上面写的重载过后的initialValue方法, 产生一个Connection对象
2、继续查看当前线程的threadLocals是不是空的, 如果ThreadLocalMap已被初始化, 那么直接将产生的对象添加到ThreadLocalMap中, 如果没有初始化, 则创建并添加对象到其中;
同时, ThreadLocal还提供了直接操作Thread对象中的threadLocals的方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这样我们也可以不实现initialValue, 将初始化工作放到DBConnectionFactory的getConnection方法中:
public Connection getConnection() {
Connection connection = dbConnectionLocal.get();
if (connection == null) {
try {
connection = DriverManager.getConnection("", "", "");
dbConnectionLocal.set(connection);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connection;
}
那么我们看过代码之后就很清晰的知道了为什么ThreadLocal能够实现变量的多线程隔离了; 其实就是用了Map的数据结构给当前线程缓存了, 要使用的时候就从本线程的threadLocals对象中获取就可以了, key就是当前线程;
当然了在当前线程下获取当前线程里面的Map里面的对象并操作肯定没有线程并发问题了, 当然能做到变量的线程间隔离了;
现在我们知道了ThreadLocal到底是什么了, 又知道了如何使用ThreadLocal以及其基本实现原理了是不是就可以结束了呢? 其实还有一个问题就是ThreadLocalMap是个什么对象, 为什么要用这个对象呢?
ThreadLocalMap对象是什么
本质上来讲, 它就是一个Map, 但是这个ThreadLocalMap与我们平时见到的Map有点不一样
1、它没有实现Map接口;
2、它没有public的方法, 最多有一个default的构造方法, 因为这个ThreadLocalMap的方法仅仅在ThreadLocal类中调用, 属于静态内部类
3、ThreadLocalMap的Entry实现继承了WeakReference<ThreadLocal<?>>
4、该方法仅仅用了一个Entry数组来存储Key, Value; Entry并不是链表形式, 而是每个bucket里面仅仅放一个Entry;
要了解ThreadLocalMap的实现, 我们先从入口开始, 就是往该Map中添加一个值:
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
先进行简单的分析, 对该代码表层意思进行解读:
1、看下当前threadLocal的在数组中的索引位置 比如: `i = 2`, 看 `i = 2` 位置上面的元素(Entry)的`Key`是否等于threadLocal 这个 Key, 如果等于就很好说了, 直接将该位置上面的Entry的Value替换成最新的就可以了;
2、如果当前位置上面的 Entry 的 Key为空, 说明ThreadLocal对象已经被回收了, 那么就调用replaceStaleEntry
3、如果清理完无用条目(ThreadLocal被回收的条目)、并且数组中的数据大小 > 阈值的时候对当前的Table进行重新哈希
所以, 该HashMap是处理冲突检测的机制是向后移位, 清除过期条目 最终找到合适的位置;
了解完Set方法, 后面就是Get方法了:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
先找到ThreadLocal的索引位置, 如果索引位置处的entry不为空并且键与threadLocal是同一个对象, 则直接返回; 否则去后面的索引位置继续查找;
过期key的清理过程
上面我们有提及ThreadLocalMap的两种过期key数据清理方式:探测式清理和启发式清理。
我们先讲下探测式清理,也就是expungeStaleEntry方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的Entry设置为null,沿途中碰到未过期的数据则将此数据rehash后重新在table数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的Entry=null的桶中,使rehash后的Entry数据距离正确的桶的位置更近一些。操作逻辑如下:
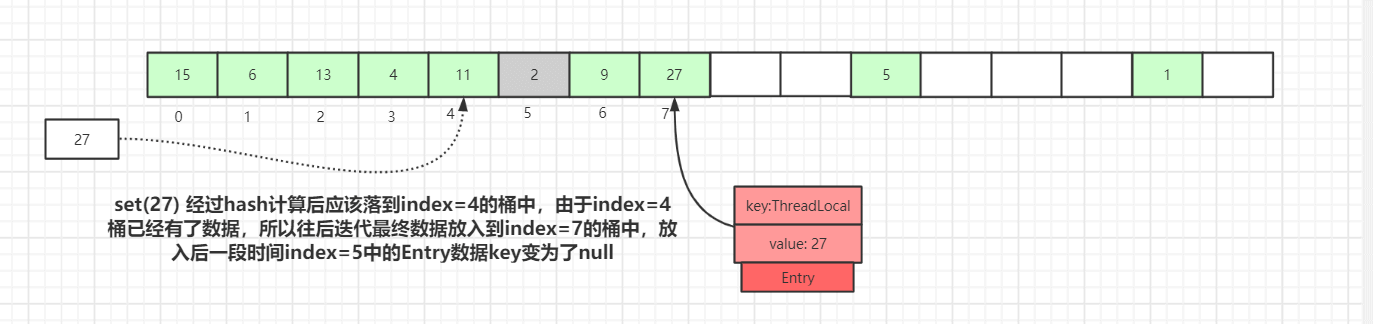
如上图,set(27) 经过 hash 计算后应该落到index=4的桶中,由于index=4桶已经有了数据,所以往后迭代最终数据放入到index=7的桶中,放入后一段时间后index=5中的Entry数据key变为了null
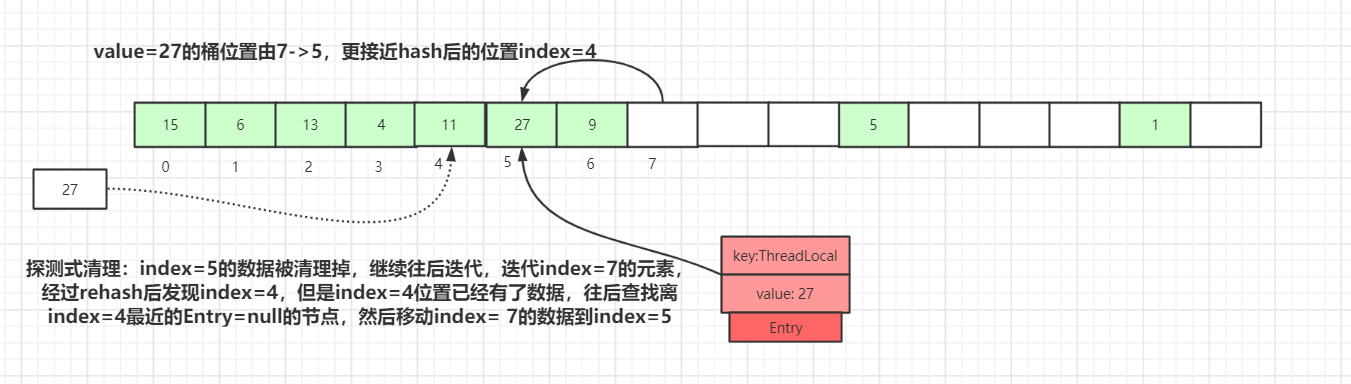
如果再有其他数据set到map中,就会触发探测式清理操作。
如上图,执行探测式清理后,index=5的数据被清理掉,继续往后迭代,到index=7的元素时,经过rehash后发现该元素正确的index=4,而此位置已经有了数据,往后查找离index=4最近的Entry=null的节点(刚被探测式清理掉的数据:index=5),找到后移动index= 7的数据到index=5中,此时桶的位置离正确的位置index=4更近了。
经过一轮探测式清理后,key过期的数据会被清理掉,没过期的数据经过rehash重定位后所处的桶位置理论上更接近i= key.hashCode & (tab.len - 1)的位置。这种优化会提高整个散列表查询性能。
接着看下expungeStaleEntry()具体流程,我们还是以先原理图后源码讲解的方式来一步步梳理:
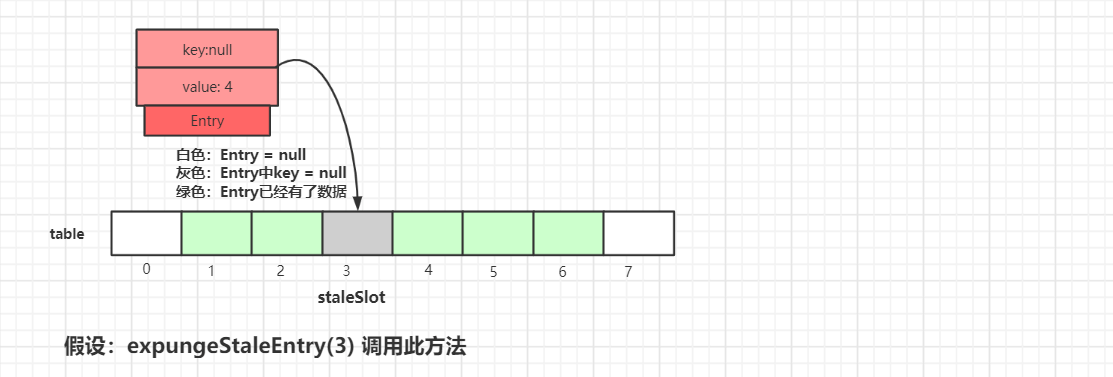
我们假设expungeStaleEntry(3) 来调用此方法,如上图所示,我们可以看到ThreadLocalMap中table的数据情况,接着执行清理操作:
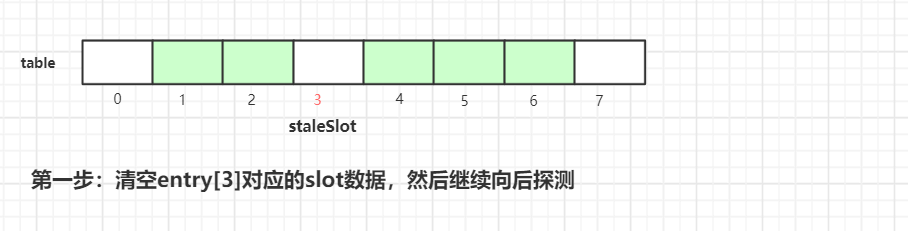
第一步是清空当前staleSlot位置的数据,index=3位置的Entry变成了null。然后接着往后探测:
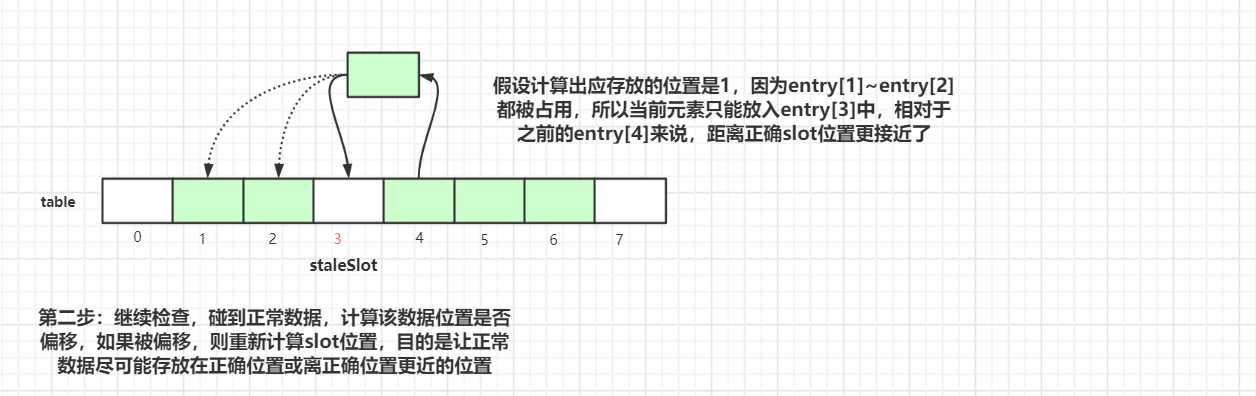
执行完第二步后,index=4 的元素挪到 index=3 的槽位中。
继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算slot位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
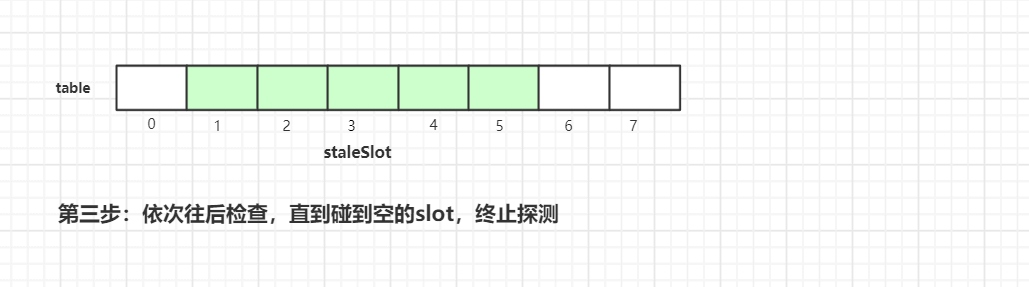
在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了,接着我们继续看看具体实现源代码:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
这里我们还是以staleSlot=3 来做示例说明,首先是将tab[staleSlot]槽位的数据清空,然后设置size-- 接着以staleSlot位置往后迭代,如果遇到k==null的过期数据,也是清空该槽位数据,然后size--
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
}
如果key没有过期,重新计算当前key的下标位置是不是当前槽位下标位置,如果不是,那么说明产生了hash冲突,此时以新计算出来正确的槽位位置往后迭代,找到最近一个可以存放entry的位置。
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
这里是处理正常的产生Hash冲突的数据,经过迭代后,有过Hash冲突数据的Entry位置会更靠近正确位置,这样的话,查询的时候 效率才会更高。
使用ThreadLocal造成内存泄露
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadLocalDemo {
static class LocalVariable {
private Long[] a = new Long[1024 * 1024];
}
// (1)
final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>());
// (2)
final static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<LocalVariable>();
public static void main(String[] args) throws InterruptedException {
// (3)
Thread.sleep(5000 * 4);
for (int i = 0; i < 50; ++i) {
poolExecutor.execute(new Runnable() {
public void run() {
// (4)
localVariable.set(new LocalVariable());
// (5)
System.out.println("use local varaible" + localVariable.get());
localVariable.remove();
}
});
}
// (6)
System.out.println("pool execute over");
}
}
我在网上找到一个样例, 如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
找到Key对应的Entry, 并且清除Entry的Key(ThreadLocal)置空, 随后清除过期的Entry即可避免内存泄露
常见方法
set(T value) 方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
set(T value) 方法中,首先获取当前线程,然后在获取到当前线程的 ThreadLocalMap,如果 ThreadLocalMap 不为 null,则将 value 保存到 ThreadLocalMap 中,并用当前 ThreadLocal 作为 key;否则创建一个 ThreadLocalMap 并给到当前线程,然后保存 value。
ThreadLocalMap 相当于一个 HashMap,是真正保存值的地方。
get() 方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
同样的,在 get() 方法中也会获取到当前线程的 ThreadLocalMap,如果 ThreadLocalMap 不为 null,则把获取 key 为当前 ThreadLocal 的值;否则调用 setInitialValue() 方法返回初始值,并保存到新创建的 ThreadLocalMap 中。
initialValue() 方法:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
initialValue() 是 ThreadLocal 的初始值,默认返回 null,子类可以重写改方法,用于设置 ThreadLocal 的初始值。
remove() 方法
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
ThreadLocal 还有一个 remove() 方法,用来移除当前 ThreadLocal 对应的值。同样也是同过当前线程的 ThreadLocalMap 来移除相应的值。
InheritableThreadLocal
我们使用ThreadLocal的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
为了解决这个问题,JDK 中还有一个InheritableThreadLocal类,我们来看一个例子:
public class InheritableThreadLocalDemo {
public static void main(String[] args) {
ThreadLocal<String> ThreadLocal = new ThreadLocal<>();
ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
ThreadLocal.set("父类数据:threadLocal");
inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("子线程获取父类ThreadLocal数据:" + ThreadLocal.get());
System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());
}
}).start();
}
}
打印结果:
子线程获取父类ThreadLocal数据:null
子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal
实现原理是子线程是通过在父线程中通过调用new Thread()方法来创建子线程,Thread#init方法在Thread的构造方法中被调用。在init方法中拷贝父线程数据到子线程中:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
this.stackSize = stackSize;
tid = nextThreadID();
}
但InheritableThreadLocal仍然有缺陷,一般我们做异步化处理都是使用的线程池,而InheritableThreadLocal是在new Thread中的init()方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个TransmittableThreadLocal组件就可以解决这个问题