主从复制和哨兵机制
主从复制和哨兵机制
主从复制概述
主从复制就是将主节点(master)的数据复制到从节点(slave),让多个节点承载用户的请求。
主从复制具备以下几个特点:
1. 数据冗余:主节点的数据都会同步到从节点上,所以多个节点都会有相同数据,从而实现数据冗余。
2. 故障恢复:主节点出现故障后,从节点可以继续承载用户的请求,做到服务上的冗余。
3. 负载均衡:主从复制机制实现主节点接收用户写请求,从节点承载用户读请求,对于读多写少的场景,这种机制可以大大提高redis的并发量。
4. 高负载:主从复制+哨兵机制可以实现高负载,这点后文会介绍到。
主从复制配置示例
一主二仆配置
创建3个redis配置文件,以笔者为例,名字分别为redis6379.conf、redis6380.conf、redis6381.conf
主节点为6379,配置内容为:
# 引入redis基本配置,注意这个配置只支持RDB
include /root/redis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
# 设置RDB文件名
dbfilename dump6379.rdb
从节点以6380,配置如下
# 引入redis基本配置,注意这个配置只支持RDB
include /root/redis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
# 作为6379的主节点
slaveof 127.0.0.1 6379
分别启动这几个redis
redis-server /root/redis/conf/redis6379.conf
redis-server /root/redis/conf/redis6380.conf
redis-server /root/redis/conf/redis6381.conf
完成配置后,我们就可以开始测试了
首先对清空主节点数据,并设置一些值进去
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set master_key value
OK
127.0.0.1:6379>
再来看看从节点
# 可以看到主节点的key来了
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> keys *
1) "master_key"
127.0.0.1:6380>
# 查看6380服务端的角色,确实是slave
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:463
slave_repl_offset:463
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:6b1f1afb6d0c0807d6f3f7b6e4118e892aba4fd2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:463
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:463
127.0.0.1:6380>
主从复制几个特点
- 从节点挂掉,在启动,数据不会丢失,照样是主节点的从节点
# 强制挂掉从节点
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> SHUTDOWN
not connected>
# 启动 发现数据都在,并且角色也是slave
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6380.conf
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_read_repl_offset:1191
slave_repl_offset:1191
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:6b1f1afb6d0c0807d6f3f7b6e4118e892aba4fd2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1191
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1164
repl_backlog_histlen:28
127.0.0.1:6380> keys *
1) "master_key"
127.0.0.1:6380>
- 主节点挂了,从节点仍然是从节点,主节点恢复后仍然是主节点
# 强制挂掉主节点
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected>
# 确定主节点下线
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# ps -ef |grep redis
root 5572 1 0 00:16 ? 00:00:01 redis-server 127.0.0.1:6381
root 6273 1 0 00:29 ? 00:00:00 redis-server 127.0.0.1:6380
root 6348 4680 0 00:30 pts/0 00:00:00 grep --color=auto redis
# 再次启动主节点,发现key都在并且角色仍然是master,设置一个k2值
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6379.conf
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli
127.0.0.1:6379> set key2 v2
OK
127.0.0.1:6379>
# 从节点仍然可以收到,说明主节点仍然是6379
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> keys *
1) "key2"
2) "master_key"
127.0.0.1:6380>
薪火相传配置
如果大量主节点配合大量从节点,会导致主节点为了同步fork大量子进程同步数据,所以我们可以将某些从节点作为某个从节点的从节点
以笔者本次示例为例,我们将81作为80的从节点
# 为了方便,笔者使用命令的形式,读者也可以使用conf文件配置
127.0.0.1:6381> SLAVEOF 127.0.0.1 6380
OK
127.0.0.1:6381>
再次查看80节点,可以看到slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=1,由此可知从节点的从节点配置完成
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:810
slave_repl_offset:810
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=1
master_failover_state:no-failover
master_replid:a0d1449bc956d9ef57489f7820340c542d0ac066
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:810
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:810
127.0.0.1:6380>
反客为主配置
对着从节点键入如下命令即可实现反客为主,这里由于配置很简单,且生产环境少用,笔者就不做过多演示了
slaveof no one
主从复制原理详解
全量复制
如下图,整体步骤为:
1. 从节点向主节点发送同步请求,因为不知道主库的runID,并且不知道同步的偏移量是多少,所以参数分别为? -1,同步请求的指令为psync
2. 主库执行bgsave指令生成rdb指令,将数据发送给从库,从库为了保证数据一致性,会将数据清空,然后加载rdb文件,完成数据同步。在此期间,主库收到的新数据都会被存入replication buffer中。
3. 主库会将replication buffer发送给从库,完成最新数据的同步。

增量复制
从 Redis 2.8 开始,因为网络断开导致数据同步中断的情况,会采用增量复制的方式完成数据补充。
需要了解的是,当主从同步过程中因为网络等问题发生中断,repl_backlog_buffer会保存两者之间差异的数据,如果从库长时间没有恢复,很可能出现该环形缓冲区数据被覆盖进而出现增量复制失败,只能通过全量复制的方式实现数据同步。
接下来我们再补充一个概念replication buffer,这个缓冲区用于存放用户写入的新指令,完成全量复制之后的数据都是通过这个buffer的数据传输实现数据增量同步。
主从复制相关面试题
- 主服务器不进行持久化复制是否会有安全性问题?
有,假如主节点没有使用RDB持久化,数据没有持久化到磁盘,假如主节点挂掉就光速恢复,从节点很可能会因此清空原本数据进而导致数据丢失。
- 为什么主从复制使用RDB而不是AOF
RDB是二进制且压缩过的文件,传输速度以及加载速度都远远快速AOF。且AOF存的都是指令非常耗费磁盘空间,加载时都是重放每个写命令,非常耗时。需要注意的是RDB是按照时间间隔进行持久化,对于数据不敏感的场景我们还是建议使用RDB。
- 什么是无磁盘复制模式
数据同步不经过主进程以及硬盘,直接创建一个新进程dump RDB数据到从节点。对于磁盘性能较差的服务器可以使用这种方式。配置参数为: repl-diskless-sync no # 决定是否开启无磁盘复制模式 repl-diskless-sync-delay 5 # 决定同步的时间间隔
- 为什么会有从库的从库设计
避免为了同步数据给大量从库,fork大量的子进程生成rdb文件进行全量复制导致主进程阻塞。
- 读写分离及其中的问题
- 延迟与不一致问题:如果对数据一致性容忍度较低,网络延迟导致数据不一致问题只能通过提高网络带宽,或者通知应用不在通过该节点获取数据
- 数据过期问题:
- 故障切换问题
- 如果在网络断开期间,repl_backlog_size环形缓冲区写满之后,是进行增量复制还是全量复制?
- 若主库的主库repl_backlog_buffer的slave_repl_offset已经被覆盖,那么同步就需要全量复制了
- 从库会通过psync命令把自己记录的slave_repl_offset发给主库,主库根据复制进度决定是增量复制还是全量复制。
哨兵模式
哨兵模式简介
哨兵提供以下几种功能
1. 监控(Monitoring):哨兵会监控主节点和从节点是否正常运作。
2. 自动故障转移(Automatic failover):当主节点因为以外下线了,哨兵就会从从节点中选出新的主节点,并让其他从节点复制新的主节点的数据。
3. 通知(Notification):哨兵会将故障转移结果通知给客户端。
4. 配置提供者(Configuration provider):客户端连接redis时,会通过哨兵获取服务提供者。
哨兵模式配置示例
编辑一个哨兵的配置文件
以笔者的为例,创建一个名为sentinel.conf,内容为如下所示,主从节点仍然以上文的6179作为主,其余作为从
sentinel monitor master_redis 127.0.0.1 6379 1
通过客户端查看6379的服务端信息,可以看到当前6379身份为master,并且有两个从节点6380和6381
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=3082,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=3082,lag=0
master_failover_state:no-failover
master_replid:3c8c2a4815e310bcc68b4e25705002a52be66658
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:3233
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:3233
127.0.0.1:6379> SHUTDOWN
not connected>
最后我们启动哨兵,然后我们将6379强制下线
redis-sentinel /root/redis/conf/sentinel.conf
然后我们就会看到主节点切换的日志信息了
8210:X 29 Aug 2022 01:01:59.772 # +failover-end master master_redis 127.0.0.1 6379
8210:X 29 Aug 2022 01:01:59.772 # +switch-master master_redis 127.0.0.1 6379 127.0.0.1 6380
哨兵模式工作原理解析
哨兵集群的组建
如下图哨兵1在主库的__sentinel__:hello频道发送消息告知其他哨兵节点,而其他哨兵也是通过订阅该节点从而使得彼此构成一张联系网。 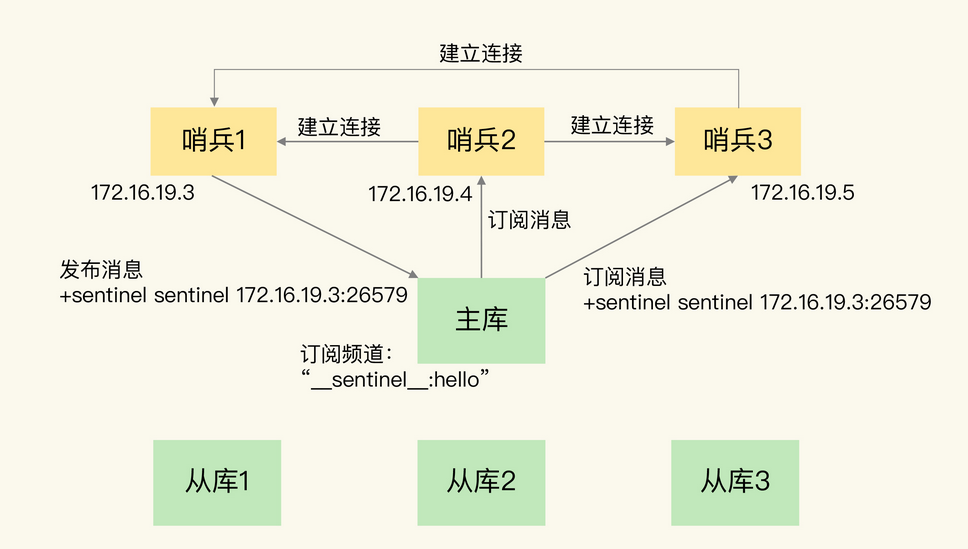
哨兵监控redis库
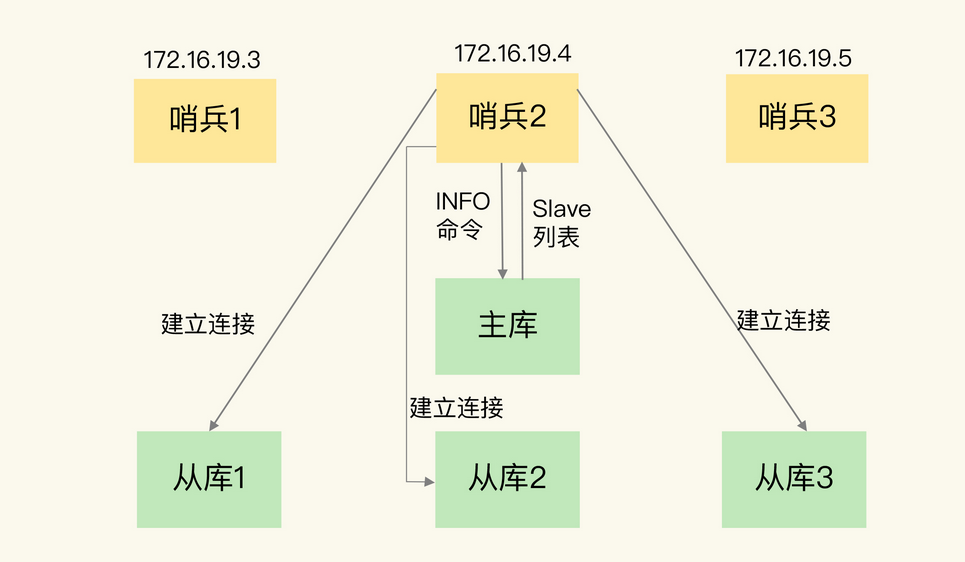
如下图哨兵通过info命令从主库中获取从库的信息,从而实现与其他从库建立连接,其他节点同理。
主库下线的判定
主观下线
任意一个哨兵对主节点进行检测判断,主节点是否下线。
客观下线
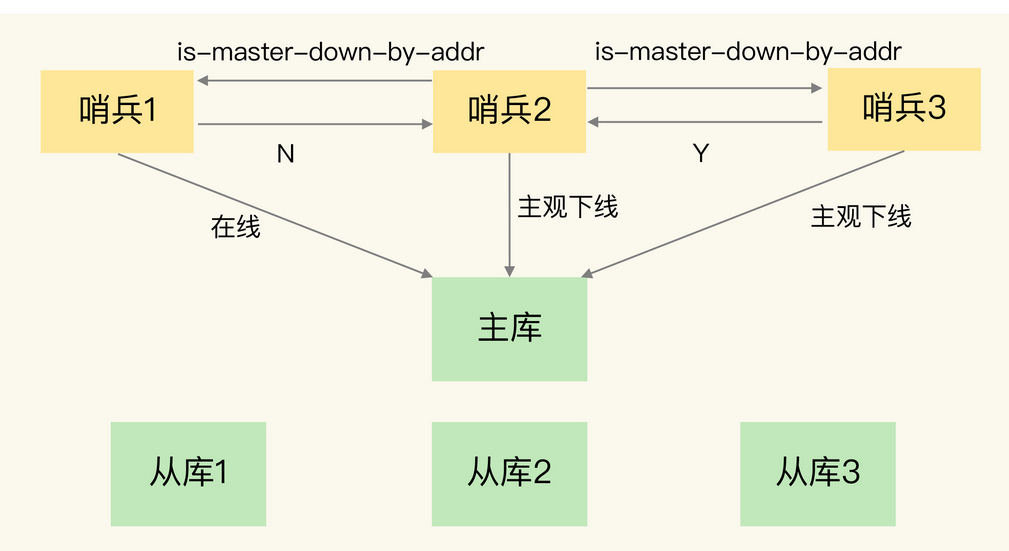
哨兵集群通过投票判定当前主节点是否下线,其工作过程如下:
1. 某个哨兵主观判定主节点下线,向其他哨兵发出is-master-down-by-addr,开始对是否下线判定进行投票
2. 每个哨兵发出自己的看法
3. 根据sentinel monitor <master-name> <ip> <redis-port> <quorum>设置quorum,若同意数大于等于quorum则判定主节点下线。
哨兵集群的选举
判定主库下线后我们就必须选出哨兵中的leader找下一个主节点,所以我们必须建立一个哨兵集群,有了集群我们必须从中选举出leader,而哨兵选举出的leader必须符合以下两个条件:
- num(total_sentinels)/2+1 //即半数(所有哨兵数的半数,无论哨兵死活)以上的选票即可成为哨兵中的leader,这就是著名的Raft算法
- 选票数还必须大于等于quorum
举个例子,假如我们当前有5个哨兵,1个主节点,3个从节点,quorum设置为2。假如此时有3个哨兵挂掉,请问我们可以判定主节点下线以及选举新的主节点嘛?
首先解决第一个问题,由于哨兵挂了3个所以还剩两个,假如主节点挂了,由于quorum等于2,所以我们有一定概率(两个哨兵都认为主节点挂了)判定主节点下线。 再来2个问题,上文已经给出了选举新的哨兵leder的两个条件,本题目明显不符合条件1,因为(5/2)+1=3,而哨兵只剩两个了,所以选不出哨兵的leader,也就没办法指定新的leader了。
主节点选出
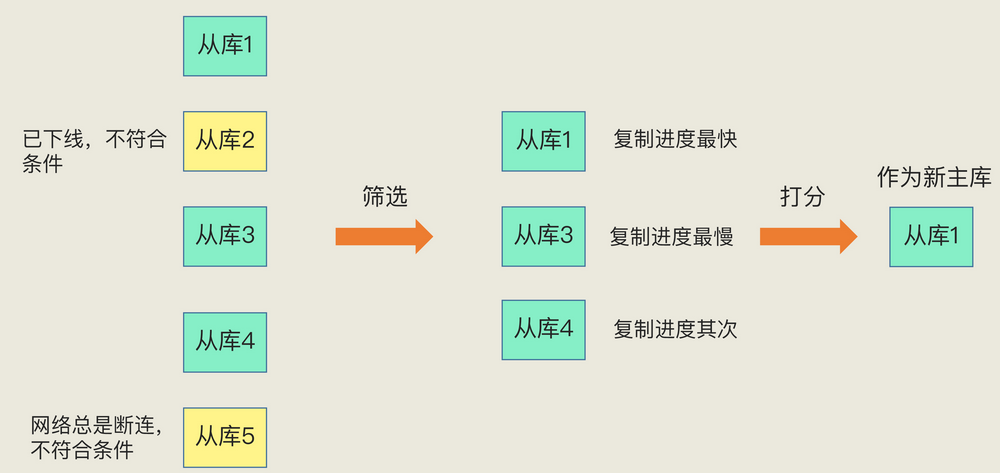
完成哨兵leader选举,就开始指定主节点了,主节点的选定规则如下:
1. 过滤掉不健康的即哨兵ping不同的从节点
2. 选择slave-priority从节点优先级高的
3. 如果不存在slave-priority配置,则选择复制偏移量(即永远原来master最多数据的节点)最大,作为主节点
故障的转移
- 选举出哨兵leader
- 哨兵leader根据上文规则选出新的master
- 从节点复制新leader的数据
- 通知客户端主节点更换
- 若原来的主节点复活,则作为新主节点的从节点