并发容器概览
并发容器概览
在并发情况下,我经常需要一些容器来存储数据,对此我们的容器就必须考虑到线程安全问题,对此jdk也在这些场景为我们提供了如下并发容器
- ConcurrentHashMap:线程安全的HashMap
- CopyOrWriteList:线程安全的list
- BlockingQueue:阻塞队列,非常适用于作为共享通道
传统的并发容器
简介
在jdk1.2版本中以及为我们提供的线程安全的同期vector和hashtable,但是他们保证线程安全的方式是使用互斥锁sync,在高并发场景下,这种方式会使得性能大打折扣。
使用实例
Vector示例以及源码解析
public class VectorDemo {
public static void main(String[] args) {
Vector<String> vector = new Vector<>();
vector.add("test");
System.out.println(vector.get(0));
}
}
通过源码我们可以看到add加了sync锁,这就是导致性能下降的主要原因
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
hashTable示例以及源码解析
/**
* 描述: 古老的线程安全的hashTable public synchronized V put(K key, V value)
*/
public class HashtableDemo {
public static void main(String[] args) {
Hashtable<String, String> hashtable = new Hashtable<>();
hashtable.put("key", "value");
System.out.println(hashtable.get("key"));
}
}
通过原本我们可以发现无论get还是set也是都加了sync锁。
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
传统容器并发缺陷
如下源码所示,不难发现这些早期的容器为了控制并发都在方法上使用了sync锁,虽然保证了线程安全,但是这种锁粒度以及锁的工作方式很明显会造成性能下降。
基于arrayList示例
读者可以通过以下的例子查看输出结果,可以发现arayList的数组长度始终不可能达到2000,原因也很简单,我们完全可以在源码中找到答案
package collections.predecessor;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* list线程不安全的示例
*/
public class baseArrayList {
public static void main(String[] args) throws InterruptedException {
final List<Integer> list = new ArrayList<Integer>();
// final List<Integer> list = Collections.synchronizedList(new ArrayList<Integer>());
// final List<Integer> list =new CopyOnWriteArrayList<Integer>();
// 线程A将0-1000添加到list
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 1000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
// 线程B将1000-2000添加到列表
new Thread(new Runnable() {
public void run() {
for (int i = 1000; i < 2000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
Thread.sleep(2000);
// 打印所有结果
for (int i = 0; i < list.size(); i++) {
System.out.println("第" + (i + 1) + "个元素为:" + list.get(i));
}
System.out.println("list:size "+list.size());
}
}
源码如下所示,可以发现arrayList在添加操作的时候需要分析对容量进行判断,假如容量不够则需要扩容,所以这期间如果多线程执行add的话,很可能出现以下几种情况: 情况1:
- 线程1在9位置插入,进行扩容判断时,发现size为10的时候才需要扩容,所以直接插入
- 线程2在线程1工作期间也进行了这样的判断和操作,由于线程2操作晚于线程1,结果线程2在size=10的位置添加元素导致了索引越界。
情况2:
线程1在9位置插入,进行扩容判断时,发现size为10的时候才需要扩容,所以直接插入
线程2在线程1工作期间也进行了这样的判断和操作,由于线程2操作晚于线程1,
ensureCapacityInternal(size + 1) elementData[size++] = e;非原子性操作,很可能导致线程1扩容并添加完成元素后,线程2的扩容导致线程1的操作全部被清空,进而导致数组大小与预期不符。
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
改进
/**
* list线程不安全的示例
*/
public class baseArrayList {
public static void main(String[] args) throws InterruptedException {
// final List<Integer> list = new ArrayList<Integer>();
final List<Integer> list = Collections.synchronizedList(new ArrayList<Integer>());
// final List<Integer> list =new CopyOnWriteArrayList<Integer>();
// 线程A将0-1000添加到list
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 1000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
// 线程B将1000-2000添加到列表
new Thread(new Runnable() {
public void run() {
for (int i = 1000; i < 2000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
Thread.sleep(2000);
// 打印所有结果
for (int i = 0; i < list.size(); i++) {
System.out.println("第" + (i + 1) + "个元素为:" + list.get(i));
}
System.out.println("list:size "+list.size());
}
}
通过源码我们可以发现,这种操作不过是基于原有list的基础上加一个sync锁,虽然起到了线程安全的作用,但也很可能出现性能下降的风险。
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
所以我们就需要介绍更加强大的并发工具CopyOrWritterList,使用代码如下所示
package collections.predecessor;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* list线程不安全的示例
*/
public class baseArrayList {
public static void main(String[] args) throws InterruptedException {
// final List<Integer> list = new ArrayList<Integer>();
// final List<Integer> list = Collections.synchronizedList(new ArrayList<Integer>());
final List<Integer> list =new CopyOnWriteArrayList<Integer>();
// 线程A将0-1000添加到list
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 1000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
// 线程B将1000-2000添加到列表
new Thread(new Runnable() {
public void run() {
for (int i = 1000; i < 2000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
Thread.sleep(2000);
// 打印所有结果
for (int i = 0; i < list.size(); i++) {
System.out.println("第" + (i + 1) + "个元素为:" + list.get(i));
}
System.out.println("list:size "+list.size());
}
}
通过源码我们可以发现,CopyOrWriteList添加保证线程安全的做法是加可重入锁,但是他每次进行写操作时都会赋值一份这就是导致大量写操作的情况下性能会十分差劲
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
但是读的情况下性能却非常优秀,没有加任何锁
public E get(int index) {
return get(getArray(), index);
}
需要唯一注意的一点是,使用CopyOnWriteArrayList迭代器时,你在何时声明迭代器,后续无论如何添加,对他遍历的结果都没有任何作用,如下所示
public class CopyOnWriteArrayListBaseUse {
/**
* 读写分离,写不改变读的遍历
* @param args
*/
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list=new CopyOnWriteArrayList<>();
// ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
Integer cur = it.next();
if (cur.equals(3)){
Integer obj=5;
list.remove(obj);
}
if (cur.equals(4)){
list.add(444);
}
System.out.println("curNode "+cur+" list "+list);
}
}
}
并发容器
先行介绍一下HashMap
HashMap和优缺点
传统HashMap(这里以jdk8为例)它底层就是基于一个数组实现的hash表,在单线程情况下,他的查找和添加、删除效率都是相当不错的。 但是,在单线程情况下,HashMap进行put操作可能会导致以下问题
- 多线程put导致数据丢失
- 多线程put扩容导致数据丢失
- 多线程put扩容导致cpu 100%
对于第三点,我们不妨先回顾以下HashMap的相关源码
添加操作源码
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
检查容量是否超标
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize(2 * table.length);
}
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
元素迁移的源代码
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next; //记录迁移节点的后继节点
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //指向新容器的第一个元素
newTable[i] = e;//新容器链表头节点指向被迁移节点
e = next; //将指向需要被迁移节点的指针,指向后继节点
} while (e != null);
}
}
}
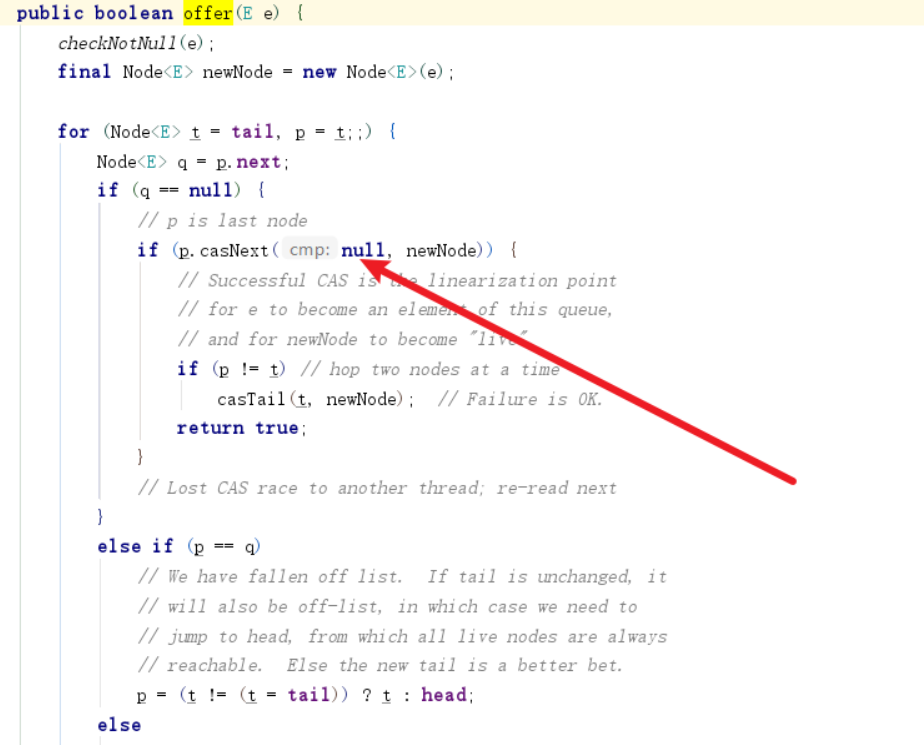
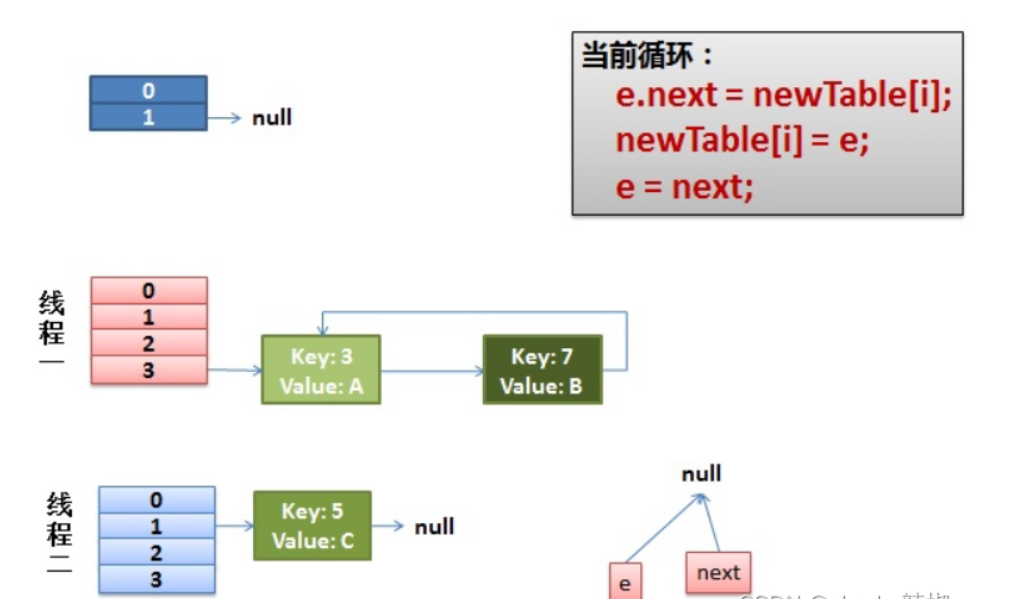
了解了这些源码之后,我们不妨描述这样一个场景,我们现在声明了一个size为2的HashMap,添加3、7、5三个元素。 可以看到添加到5之后容量就超过2了。 所以我们需要进行元素迁移。 按照transfer代码来看,在单线程情况下3、7还是会被迁移到同一个槽位中。
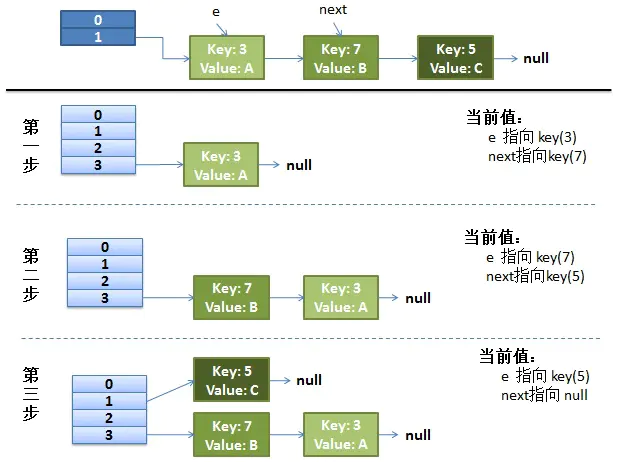
我们再来看看多线程情况下的bug。假如多线程情况下,我们线程1执行到Entry<K,V> next = e.next; //记录迁移节点的后继节点被挂起。线程完成像上文单线程的迁移操作。
线程1拿到cpu时间片再次回来执行。他会完成这样下述步骤:
- 将key 3的元素的next指针指向线程1开辟的新容器的首节点,即null
- 新容器指向key为3
- e指针指向7
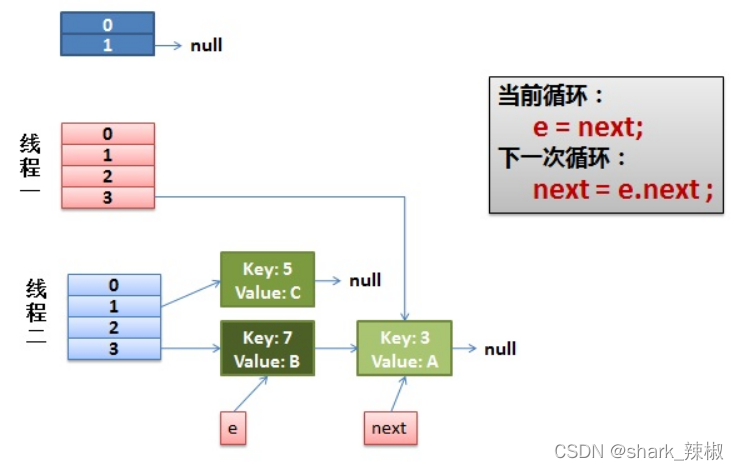
然后在进行如下操作:
- next指向3
- 7的next指向新容器槽位3的第一个元素,即3
- 新容器头指针指向7
- e指向3
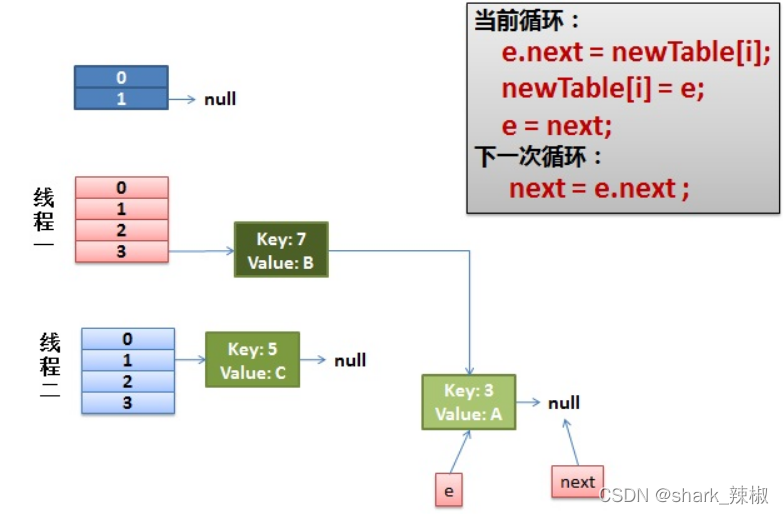
最后我们会执行这样一个步骤:
- next指向7
e.next = newTable[i]3的next指向新容器的next即7于是环形链形成,cpu就此被打爆。
为什么jdk8的HashMap会在链表长度超过8的时候转为红黑树
这里我们也可以补充一个有趣的事情,为什么jdk8的HashMap会在链表长度超过8的时候转为红黑树,当离散算法设计良好的话链表长度到达8的概率不到千分之一,假如你的链表长度达到8就说明你的hash算法设计的有问题,这时候就需要转为红黑树了
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
图示以及源码了解ConcurrentHashMap在jdk7和jdk8的区别
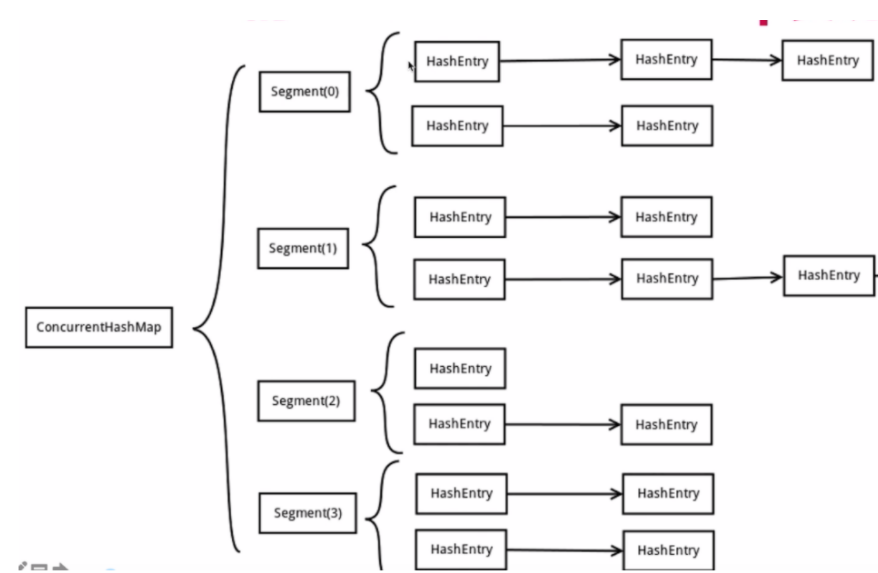
如下图所示,jdk7的concurentHashMap,可以看出jdk7版本的ConcurrentHashMap最外层是一个segment,内部结构就是和jdk7版本的HashMap一样的结构,依然是数组+链表形成的拉链法键值对。 而且每个segment都会持有一个reentrantLock,这使得各自的并发操作是互相不会影响的。所以你有几个segment就支持几个并发操作。 同样的缺点也很明显,正是因为这样的操作,导致我们若手动指定segment就会导致map无法进行扩容操作。
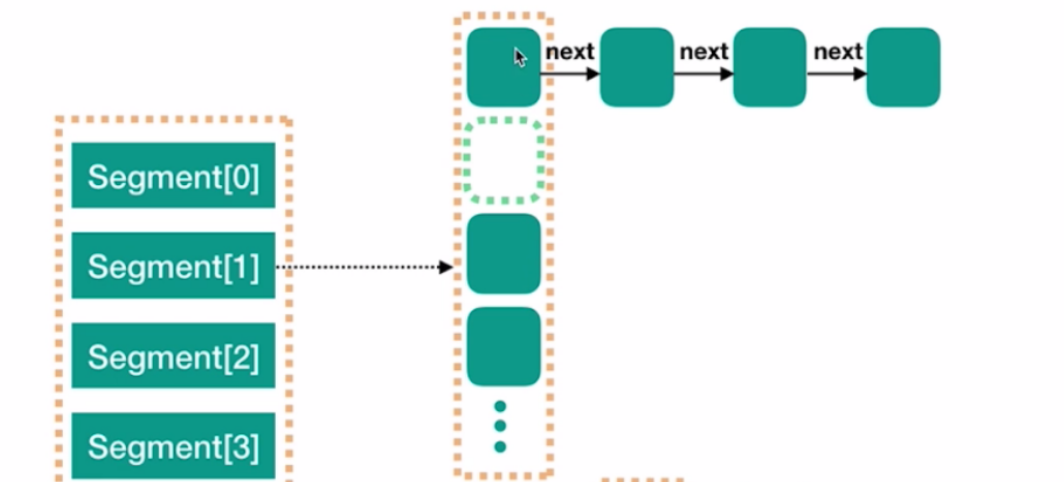
相比之下jdk8版本的ConcurrentHashMap就与传统的HashMap无异了。
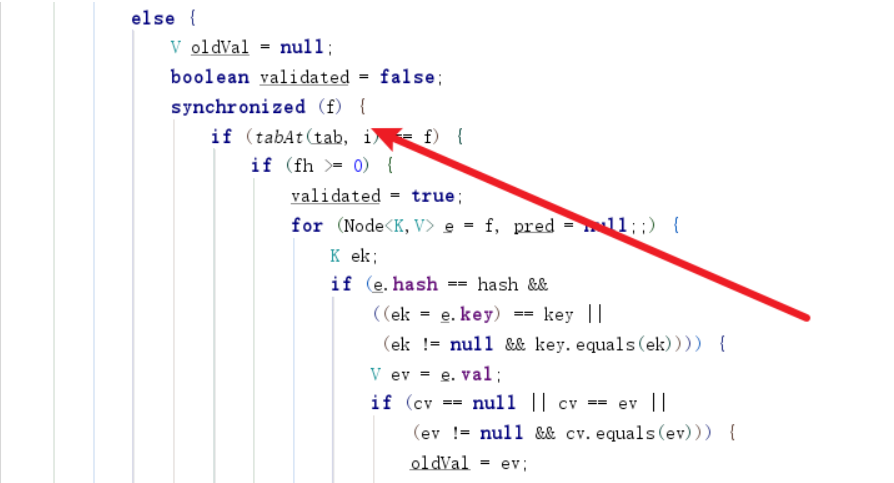
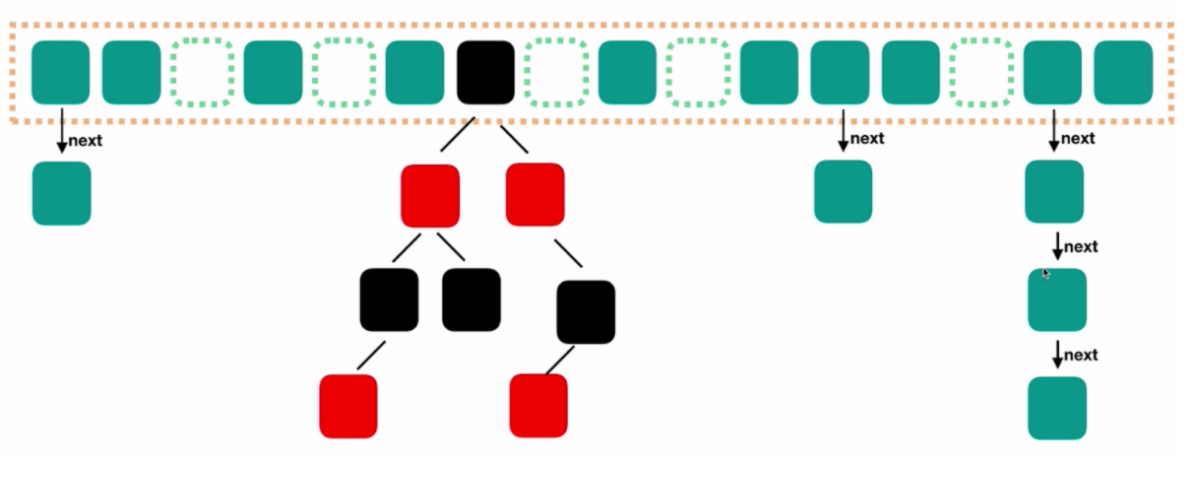 从源码中我们也能看出ConcurrentHashMap实现线程安全的核心核心
从源码中我们也能看出ConcurrentHashMap实现线程安全的核心核心
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//计算f在表的哪个位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//使用节点作为锁完成元素添加操作
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果key的值一样则执行覆盖逻辑
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//如果后继节点为空则执行后继插入操作
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
ConcurrentHashMap使用注意事项
如下所示,由于+1并不是原子操作,所以这样使用很可能导致线程安全问题
/**
* 描述: ConcurrentHashMap错误使用示例
*/
public class ConcurrentHashMapDemo implements Runnable {
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
map.put("k", 0);
Thread thread1 = new Thread(new ConcurrentHashMapDemo());
Thread thread2 = new Thread(new ConcurrentHashMapDemo());
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(map.get("k"));
}
/**
* 线程不安全示例
*/
@Override
public void run() {
if (map.containsKey("k")) {
for (int i = 0; i < 1000; i++) {
map.put("k", map.get("k") + 1);
}
}
}
}
所以正确方案可以是如下两种,需要了解的是第一种锁粒度太大了,建议使用ConcurrentHashMap提供的第二种解决方案
/**
* 使用sync示例
*/
@Override
public void run() {
if (map.containsKey("k")) {
for (int i = 0; i < 1000; i++) {
synchronized (ConcurrentHashMapDemo.class) {
map.put("k", map.get("k") + 1);
}
}
}
}
/**
* 最佳线程安全使用示例
*/
@Override
public void run() {
if (map.containsKey("k")) {
for (int i = 0; i < 1000; i++) {
while (true){
int old=map.get("k");
int newVal=old+1;
boolean b = map.replace("k", old, newVal);
if (b){
break;
}
}
}
}
}
通过源码我们就能发现它使用的添加操作工作原理和上述put差不多,锁也是锁节点,而不像我们一样锁一个类,减少了粒度,提高了性能。
阻塞队列
简介
队列的作用在并发编程中也是非常重要的,通过并发队列,我们可以使用生产者和消费者模式的方式完成,数据在线程间的传递,同时也将线程安全的问题从我们转移到队列上。
图解阻塞队列工作机制
如下图所示,阻塞队列就是典型的生产者和消费者模式,当队列满时put就会阻塞,当队列为空时get就会为空。

阻塞队列常见方法
- put、take:添加或取出操作可能会阻塞
- add、remove、element:添加取出时可能会报异常
- offer、poll(取出时会删除该元素)、peek:第三组操作完成后会有返回值
ArrayBlockingQueue
如下所示,这就是典型阻塞队列用法,通过下属示例就会发现当队列满的时侯,就会阻塞put操作。
package collections.queue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ArrayBlockingQueueTest {
public static void main(String[] args) {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
Producer producer = new Producer(queue);
Consumer1 consumer1 = new Consumer1(queue);
new Thread(producer).start();
new Thread(consumer1).start();
}
}
class Producer implements Runnable {
private BlockingQueue<String> queue;
public Producer(BlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
System.out.println("有10个人前来面试");
for (int i = 0; i < 10; i++) {
try {
queue.put("候选人" + (i + 1));
System.out.println("候选人" + (i + 1)+"入座");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
queue.put("stop");
System.out.println("候选人全部入队");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Consumer1 implements Runnable {
private BlockingQueue<String> queue;
public Consumer1(BlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
//睡一会让生产者阻塞
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String man;
try {
while (!("stop".equals(man = queue.take()))) {
System.out.println(man + " 面试中。。。。。");
}
System.out.println("面试结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
其他队列简介
LinkedBlockingQueue
- 默认无界队列
- 如下所示,使用两把锁完成入队和出队操作
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
PriorityBlockingQueue
- 支持优先级
- 自然顺序
- 无界队列
SynchronousQueue
容量为0的队列
直接传递数据
cacheThread专用队列
ConcurrentLinkedQueue
非阻塞队列,使用cas完成数据操作